https://www.riss.kr/search/detail/DetailView.do?control_no=6f27258c75b816a1ffe0bdc3ef48d419&p_mat_type=be54d9b8bc7cdb09
www.riss.kr
※ 해당 논문을 분석하여 작성한 글입니다.
연구 배경
연구 목표(차별점)
연구 이론
- 딥러닝
- 베이즈 정리
연구 방법
- 데이터베이스 구축
- 네트워크 구성 및 학습 방법
- 베이즈 이론 적용 방법
실험 및 결과
- 실험환경
- 평가방법
- 실험결과
연구 배경
자동차는 미끄러지는 것을 방지하기 위한 ABS( Anti-Lock brake system )시스템 장착이 의무화 되었다.
자율주행 자동차는 노면의 상태를 스스로 인지하고 판단하여 다양한 노면에서도 안전한 주행을 제공해야 한다.
따라서 본 논문에서는 딥러닝을 활용하여 차량이 주행 중 실시간으로 노면의 상태를 예측할 수 있도록 하고 신뢰성을 높이기 위해 확률 업데이트 알고리즘을 제안한다.
* ABS
정지된 물체가 막 움직이기 바로 직전에 마찰력이 최대가 된다는 최대 정지마찰력의 원리를 이용하여 타이어가 잠기는 위험한 상황을 방지하여 안전성을 높여주는 전자제어 브레이크 시스템
연구 목표(차별점)
선행 연구 : 입력 데이터의 용량이 크거나 네트워크 깊이가 깊어서 실행 메모리가 크다는 단점
-> 자동차가 실제 주행을 할 때 노면을 예측할 수 있도록 경량화된 네트워크를 제안
-> 차량의 엔진 제어 장치에서 실시간으로 예측할 수 있도록 네트워크를 경량화하고 확률 업데이트를 통해 신뢰도를 높이는 네트워크를 제안
- 실제 차량이 다양한 노면에서 주행하여 취득된 센서 값을 활용 한다. 활용하는 데이터는 시계열 데이터로 어떠한 연속적
인 시간에서 사건을 예측 하는 특징
- 따라서 제안한 네트워크에서 도출되는 확률을 그대로 사용하지 않고 네트워크의 이전 예측 확률을 사용해 현재시간의 예측 확률을 추정
> 추가적인 센서 사용 없이 자동차 내부 CAN(Controller Area Network) 통신으로 얻어지는 데이터를 활용하여, 입력 데이터를 경량화하고 도출된 확률을 활용하여 정확도를 향상시키는 방법을 제안
11개의 다양한 노면에서 목표 속도에서의 등속 주행(오차 ±10km) 한 시계 열 데이터를 활용한다. 학습 네트워크는 MLP(Multi Layer Perceptron)를 사용 하여 연구를 진행하고 실제 자동차에 탑재하여 실시간으로 노면 예측을 진행 하기 위해 경량화한 네트워크를 사용한다.
* CAN
CAN(Controller Area Network)이란, 차량 내에서 호스트 컴퓨터 없이 마이크로 컨트롤러나 장치들이 서로 통신하기 위해 설계된 표준 통신 규격입니다. 차량 내 ECU(Electronic control unit)들은 CAN 프로토콜을 사용하여 통신
* ECU
자동자의 다양한 장치(기기)를 제어하는 역할을 하는 전자제어 장치
* 시계열 데이터
일정한 시간 동안 수집된 일련의 순차적으로 정해진 데이터 셋의 집합. 시계열 데이터의 특징으로는 시간에 관해 순서가 매겨져 있다는 점과, 연속한 관측치는 서로 상관관계를 갖고 있다.
연구 이론
기계학습(Machine Learning, ML) : 컴퓨터가 스스로 대량의 데이터를 분석 하여 특징을 찾아내어 결론을 도출하는 기법
- 지도학습 (Supervised Learning)
정답을 알고 있는 데이터를 활용하여 학습을 진행하여, 처음 보는 데이터를 예측
분류(Classification) : 주어진 데이터 세트를 분석하고 이때, 원하는 개수의 범주(Categorical)로 구분하는 것
회귀(Regression) : 연속된 값을 예측하는 것
- 비지도 학습(Unsupervised Learning)
데이터의 정답 값을 알지 못함
데이터를 분석하여 의미 있는 데이터를 추출할 수 있고, 유사한 데이터에 대해서 군집화(Clustering)
하나의 군집(Cluster) 내의 데이터는 서로 유사하고, 다른 군집의 데이터와는 유사도가 떨어짐
- 강화학습 (Reinforcement Learning)
머신러닝은 특징 추출 단계에서 사용자가 직접 특징 추출을 하는 Hand-crafted feature 방식을 사용하여 학습을 진행한다.
딥러닝은 머신러닝의 하위 개념으로 특징 추출 단계까지 모두 학습 단계에서 모델이 스스로 데이터의 특징을 추출하여 학습을 진행
1.1 Multi Layer Perceptron
MLP(Multi Layer Perceptron)는 입력 계층(Input layer)과 출력 계층 (Output layer) 사이에 여러 개의 은닉 계층(Hidden layer)들로 이루어진 인공 신경망(Artificial Neural Network, ANN)이다.

각 계층은 여러 개의 유닛(Unit)으로 이루어져 있다. 입력 계층과 은닉 계층, 출력 계층은 모두 완전 연결(Fully Connected) 형태로 완전 연결 네트워크 (Fully Connected Network, FCN)라고도 부른다.
각각의 은닉 계층에서 매개변수 가중치(Weight)와 편향(bias) 연산을 진행하고 출력 계층에서 예측 결과를 도출한다.
1.2 Long Short-Term Memory
MLP는 학습 데이터의 특성을 독립적으로 판단하여 특성을 순서를 중요하게 생각하지 않는다. 이에 과거의 정보로 현재 정보를 예측하는 데 사용하고, 현재의 정보로 미래를 예측하는 순환 신경망(Recurrent Neural Network, RNN)이 개발되었다. 순환 신경망은 입력과 출력을 시퀀스 데이터를 처리하기 위해 모델링 되어 문장, 단어, 시계열 데이터에 효과적이다.
최초 시점의 정보가 먼 미래의 시점까지 제대로 전달되지 않는 정보 손실이 발생하게 된다. 이러한 문제를 보완하기 위해 장기 메모리와 단기 메모리를 따로 관리하여 최초 시점의 정보가 유지될 수 있도록 하는 장단기 메모리(Long Short-Term Memory, LSTM)가 개발되었다.
LSTM은 RNN과 같은 체인 구조를 갖추고 있지만, 반복 모듈은 다른 구조를 가진다.
LSTM은 하나의 블록 내에 다르게 작용하는 삭제 게이트(Forget gate), 입력 게이트(input gate), 출력 게이트(output gate)로 총 3개의 게이트와 장기 기억을 전달하는 Cell state가 있다. 게이트는 선택적으로 정보를 전달하는 방법으로 각 게이트를 연결하는 선은 전체 벡터를 전달하는 의미

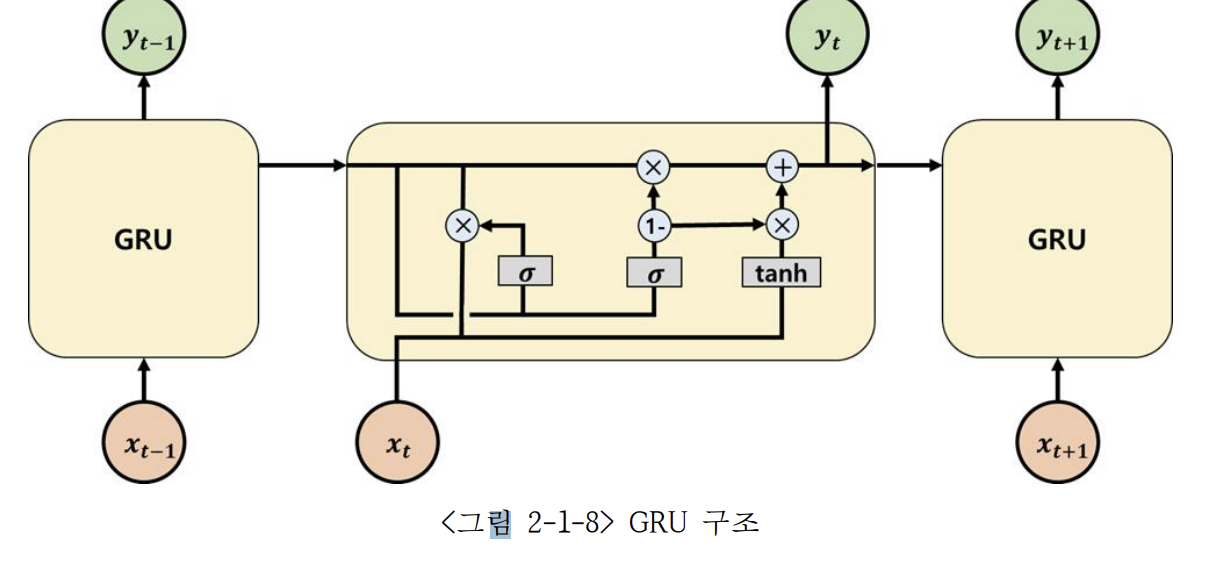
1.3 Gated Recurrent Unit
GRU(Gated Recurrent Unit)는 LSTM의 구조를 간단하게 개선한 모델이다.
LSTM에는 크게 3개의 게이트(입력 게이트, 삭제 게이트, 출력 게이트)가 존재하지만, GRU에서는 2개의 게이트를 사용한다. LSTM의 삭제 게이트 (Forget gate)와 입력 게이트(Input gate)의 역할을 하는 업데이트 게이트(e)를 가지고 있다. GRU의 게이트는 삭제 게이트(Forget gate)와 업데이트 게이트 (Update gate)로 이루어져 있다.
연구 방법
딥러닝 학습 알고리즘을 사용하여 노면 상태 판단 방법을 제안

1.1 데이터 개요
- 데이터 취득 : 실제 자동차 주행 CAN(Controller Area Network) 데이터
* 100Hz 속도로 취득
* ‘Asphalt’, ‘Wet Asphalt’, ‘Gravel’, ‘Wet Gravel’, ‘Ice’, ‘Snow’, ‘Mud’, ‘Wet Mud’, ‘Wide Low Friction’, ‘Wet Wide Low Friction’ 그리고 자동차 휠 좌ㆍ우측의 노면이 다른 경우 를 나타내는 ‘Split’ 총 11개 데이터
가. 데이터 취득 환경
- 현대자동차 크레타(CRETA)를 한 대 사용
- 스웨덴 윈터 테스트(Winter test), 자동차안전 연구원(KATRI) 주행시험장에서 취득
- 7초에서 약 5분 정도의 주행을 진행
- 각각의 노면에서 다양한 목표 속도를 설정. 설정한 목표 속도까지 올려 도달한 이후에는 최대한 브레이크를 밟지 않고 등속 주행을 목표로 데이터를 취득
나. 데이터 취득 인자
- 학습 데이터 인자 : 차체 움직임 관련 정보, 기울기와 관련된 정보, 가 ㆍ감속 관련 정보, 조향 관련 정보
- 학습에 사용하는 인자는 총 13개
다. 데이터 노이즈 제거
- 주파수에 의해 각각의 바퀴의 속도를 검출하는데, 신호 펄스의 진동 혹은 잡음(Noise)을 없애기 위해 1차 저주파 통과 필터(Low-Pass Filter, lpf)를 사용
- 1차 저주파 통과 필터는 오래된 측정값과 현재 측정값을 같은 비중으로 취급하는 이동평균 필터를 보완한 필터
1.2 입력 데이터 전처리
가. Data Scaling
학습 데이터의 Scale 차이가 큰 경우, 값이 큰 특성에 영향을 많이 받을 수 있다. 이는 경사 하강법(Gradient Descent)의 관점에서는 데이터가 넓게 분포해 있을수록 수렴 과정이 복잡하고, 시간이 오래 소요된다. 이에 데이터 스케일링(Data scaling)을 진행하면 수렴 속도 빨라지는 효과가 있다.
- 표준화(Standardization)
학습 데이터를 평균 0, 분산 1이 되는 정규 분포로 변환
데이터의 평균값과 분산값을 사용하여 이상치가 들어와도 데이터를 변환할 수 있음.
- 정규화(Normalization)
학습 데이터 특성들의 범위를 0에서 1의 값(MinMax Scaler)으로 변환
학습에 사용한 데이터의 범위 내에 있지 않은, 이상치(Outlier) 가 들어왔을 때 제대로 작동하지 않는 단점
나. 속도 전처리
목표 속도까지 올려 목표 속도에 도달한 후에는 브레이크를 최대한 밟지 않고 데이터를 취득하는 것이 목표였지만 사람이 직접 운전하는 것으로 목표 속도에서 오차(±10km)를 허용하여 주행 데이터를 취득
1.3 Label 전처리
주행 시 자동차에 장착된 카메라를 활용하여 카메라의 시간과 데이터의 시간을 비교하여 라벨링을 진행

1.4 데이터 구성
지도학습의 경우, 데이터의 불균형으로 하나의 Label이 많을 경우, 학습을 진행하면서 하나의 노면으로 예측하는 적절하지 않은 학습이 이루어질 수 있다.
이러한 데이터 불균형 시에 사용하는 기법이 있다.
데이터 과정에서 학습 데이터를 Resampling 하는 방법과 학습 과정에서 가중치를 다르게 반영하는 Class weight 방법
1) 시계열 데이터를 Up-sampling 하는 방법으로는 늘어난 시간의 공간을 실제 데이터로 채우는 방법
=> 데이터 복사
=> 선형 보간(Linear interpolation) - 실제 데이터 사이에 비어있는 값을 선형으로 계산하여 채우는 방법
2) Down-sampling 방법으로는 주기를 바꾸는 것으로 데이터의 빈도를 낮추는 방법
실험 및 결과
제1절 실험 환경
- 딥러닝 모델의 학습을 진행하기 위해 CUDA 병렬 연산이 가능한 GPU를 활용
- 기본 OS는 Ubuntu 20.04를 사용했으며, 개발 언어는 MATLAB(매트랩)을 사용
- MATLAB의 Deep Learning Toolbox를 사용하여 모델 개발을 진행했으며, 스크립트 기반으로 개발을 진행
* CUDA
CUDA 는 엔비디아가 자체 GPU에서의 일반 컴퓨팅을 위해 개발한 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델이다.
CUDA는 개발자가 연산의 병렬화할 수 있는 부분에 GPU의 성능을 활용해 컴퓨팅 집약적인 애플리케이션의 속도를 높일 수 있도록 해준다.
* MATLAB (유료)
기계어를 이해하고 싶어서 만든 것보다는 수학적 계산, 여러 신호 처리, 영상 처리, A.I.와 관련한 다양한 수치해석 등 다양한 형태에 대한 수치를 다루기 위해 만들어졌다. C언어 보다 더 고수준 언어이지만, 다양한 공학과 관련한 수학적 연산이 매우 빠르기에 많이 사용된다.
제2절 평가 방법
- 분류 네트워크의 성능을 도출할 수 있는 Confusion Matrix를 활용
Confusion Matrix에 사용되는 용어는 TP(True Positive), FP(False Positive), FN(False Negative), TN(True Negative)이 있다.
TP : 실제 값이 True이고 네트워크의 예측값도 True로 예측한 경우
TN : 실제 값이 False고 네트워크의 예측값도 False로 예측한 경우
TP, TN : 정답 값을 올바르게 예측한 경우로 높을수록 네트워크의 성능이 좋다.
FP : 실제 값이 False인데 네트워 크의 예측값은 True로 예측한 경우
FN : 실제 값은 True인데 네트워크의 예측은 False로 예측한 경우
FP, FN : 정답 값을 올바르게 예측하지 못한 경우로 높을수록 네트워크의 오인식하는 경우가 많다는 뜻이다.
이러한 용어를 사용하여 나타내는 대표적인 성능지표로는 정확도 (Accuracy), 정밀도(Precision), 재현율(Recall), F1 Score가 있다.
정확도 : 가장 많이 사용하는 성능지표. 전체 데이터의 개수에서 올바르게 예측한 데이터의 비율을 도출한다.
정밀도 : True라고 분류한 집단에서 실제로 True가 얼마나 있는가에 대한 비율을 도출한다.
재현율 : 실제 True인 집단에서 True로 예측한 비율을 도출한다.
F1 Score : 수식에 사용된 것처럼 정밀도와 재현율의 조화 평균값이라고 불리며, 성능을 0에서 1 값으로 도출한다. 수식에서 사용되는 정밀도와 재현율이 어느 한쪽의 값이 큰 경우보다 조화롭게 큰 값을 가질 때 F1 Score가 더 높다.
* 데이터가 불균형할 때 성능지표로 정확도를 쓴다면 정확한 성능을 알아내기 힘들다.
특정 클래스의 데이터가 다른 클래스보다 월등히 많은 경우를 예시로 들면, 특정 클래스의 데이터가 많아 그 클래스로 모두 예측했다면 정확도는 높게 측정될 것이다
제3절 실험 결과
제안하는 경량화된 모델과 확률 업데이트를 통해 평균 재현율 0.93을 도출하였으며 데이터 예측 시간 0.008초를 도출
로 11 개의 노면에서 Recall 기준으로 0.93의 정확도를 도출하였으며 조화 평균치 F1 Score 0.77을 도출하였다. 결과를 도출하고 결과 업데이트를 진행하는 데 소요 되는 시간은 CPU 기준으로 0.008초이다.
결론
- Deep Neural Network 기반의 가장 알맞은 경량화 모델을 제안하고, 네트워크의 한계점을 보완할 수 있는 확률 추론을 제안하여 최적의 솔루션을 제안
- 자동차의 내부 CAN 데이터를 활용하여, 자동차 자세 정보, 가감 속 정보, 조향, 각 휠의 속도 등의 인자를 사용하여 최종 11개의 노면을 예측
- 분류 네트워크의 성능을 나타내기 위해 Confusion matrix를 사용하고 정확도, 정밀도, 재현율, F1 score를 성능 지표로 사용
- 본 연구를 통해 입력 시간을 길게하고, 네트워크의 복잡도를 증가시키지 않고 확률 업데이트를 통해 성능이 향상됨을 확인
논문 선정 이유
길고 모르는 어휘들로 가득하지만 개념 설명도 간략하게 함께 되어있어, 개념 정리하면서 접근해보기 좋을 것 같아 선정하였다.
Reference
Part_01:: 자동차 전자제어장치 ECU란 무엇인가?
오늘부터 차근 차근 이 분야(Connected Car, Smart Car)에 대해서 포스팅을 해 볼 생각입니다. ...
blog.naver.com
[Matlab] Matlab이란?
Matlab이란? 무엇인가? 우리는 왜 Matlab을 써야하는가? 일단 Matlab이란 파이썬과 비슷하게 자연어에 가까운 고수준 언어이다. 여기서 고수준이란 수준이 높다는 것이 아닌 기계어 (이진수로 표현된
studium-anywhere.tistory.com
시계열 데이터란? & 시계열의 종류
시계열 데이터란? & 시계열의 종류 시계열 데이터란 일정한 시간 동안 수집 된 일련의 순차적으로 정해진 데이터 셋의 집합입니다. 시계열 데이터의 특징으로는 시간에 관해 순서가 매겨져 있다
sodayeong.tistory.com